The Python Dreamteam
Originally published in Towards Data Science.
As a Data Scientist, I code almost entirely in Python. I also get easily scared by configuring stuff. I don’t really know what a PATH is. I have no clue what lies within the /bin directory on my laptop. These are all things that you seemingly have to get familiar with to not have Python implode on your system when you try to change anything. Over some years of struggle I stumbled upon the pipenv/pyenv combo, which seems to have largely solved my Python setup woes in a way that mostly makes sense to me.
Until recently I used a Homebrew installation Python 3 with venv as my Python dependency wrangler. Mostly, venv worked great for me. It’s been included in Python since 3.3, so it feels like a first class citizen in the Python ecosystem. Storing a directory full of virtual environments, and typing out a whole path anytime I wanted to create or activate one, felt weird but seemed to work just fine. After encountering an issue installing TensorFlow with Python 3.7.0 as installed by Homebrew, I decided to look for an alternative.
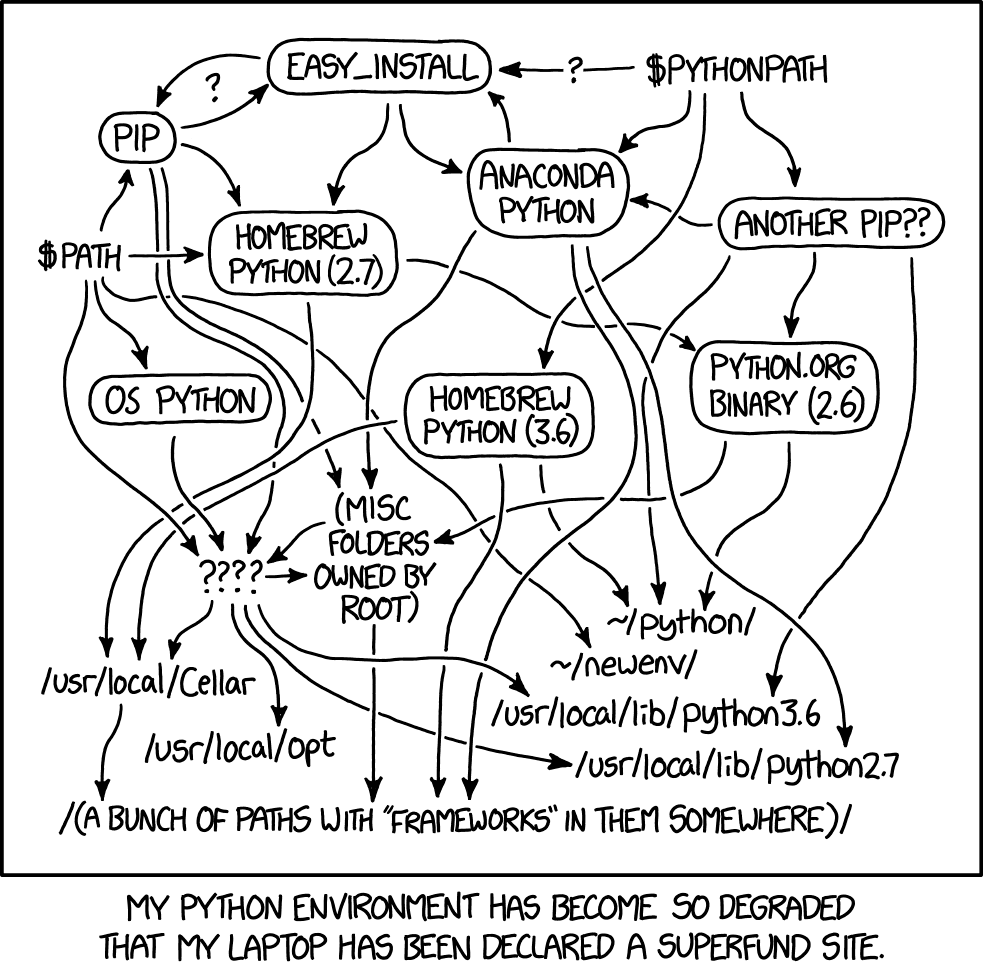
For some context, my workflow for a project starts with cloning a standard research repository, using a tool called Cookiecutter. This standard repo has a handy default requirements.txt (with Jupyter, TensorFlow etc), and a consistent directory structure that helps us keep our research projects nice and neat. In order to be able to revisit a project in a few months/years, it’s key to record the specific versions of all dependencies to allow that project’s environment to be easily recreated. This also lets others get your project working on their system! Previously with venv, I wrote a Makefile that would write the specific versions to a requirements_versions.txt. This wasn’t ideal, since it wouldn’t record the specific Python version, and sometimes you’d forget to run the Make commands.
Based on my workflow and previous experiences with venv, I had some key requirements:
- Seamlessly record specific Python/package versions.
- Play nicely with multiple Python versions.
- Keep stuff within the project directory as much as possible.
pyenv
pyenv is a super nice tool for managing multiple Python versions alongside each other. You can easily set your global Python version, launch a shell using a specific version, or set a version for a specific project.
On MacOS, installation was relatively straightforward:
xcode-select — installbrew install openssl readline sqlite3 xz zlibbrew updatebrew install pyenv- Add
eval “$(pyenv init -)”to your shell configuration file. exec “$SHELL”
Now you can easily install and use different Python versions with pyenv’s simple commands. These include pyenv install to install a specific version, pyenv global to set to set the global version, and pyenv local to set a directory-specific version. You can also use an environment variable, PYENV_VERSION, to set the version for a specific session.
pipenv
pipenv is, in my opinion, the best package manager for python. It automatically creates and manages virtual environments for your projects as you go. It also works with pyenv to install and use python versions as required, which is life changing.
On MacOS, installation is as easy as:
brew install pipenv
Because it’s installed independently, you also won’t get any of those weird,
You are using pip version 9.0.1, however version 18.0 is available.
that never seem to go away.
pipenv works with a Pipfile instead of a requirements.txt. When you first run pipenv install (which you can use just like pip install) in a project directory, it will create a Pipfile in that directory. You can even install from a requirements.txt using pipenv install -r requirements.txt. This file will automatically update when you install, remove, or update packages. It also records your python version! Activating the environment is as simple as running pipenv shell from that project’s directory. No more trying to remember where you put your environment or what you called it!
Conclusion
It’s super easy to ignore proper package version management, especially as a Data Scientist. However, the problems improper version management cause can really add up. From not being able to have collaborators run your code, to not being able to run your own code a few months down the line, you can easily waste a lot of time fixing dependency issues. It can also be a frustrating thing to get right. For me, the pipenv/pyenv combo has been a treat to work with. It automates the right amount of stuff, without sacrificing consistency.